

Pattern Recognition
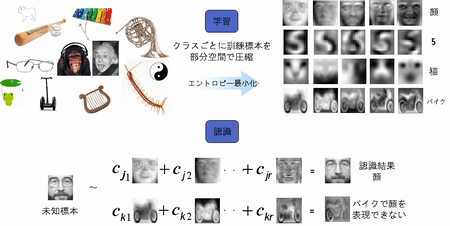
文字や顔など,この世界に存在するさまざまな物体を圧縮的に表現し,それらを機械に対して高速かつ高精度に認識させる手法について研究を行っています.物体(パターン)を圧縮することで,認識に重要な成分を抽出でき,限られた記憶容量で多様なパターンを効率的に表現することが可能となります.その結果,処理の高速化や高精度化が期待できます.このような特性を活かすことで,計算能力や記憶容量の制約がある携帯端末上でも物体の認識・検出が可能となり,機械にとって困難な認識課題も効率的に解決できるようになります.
Classifier design is one of the most critical topics in the field of pattern recognition. Our laboratory focuses on a linear classification technique known as the subspace method. This method projects high-dimensional input samples onto a low-dimensional subspace derived through eigenvalue decomposition of the autocorrelation matrix. By representing each input as a linear combination of a few eigenvectors, this method enables both efficient compression and accurate classification. These characteristics contribute to achieving high recognition accuracy and fast processing speed during classification.
Multimedia Understanding -Manga analysis-

キングダム©原泰久/集英社
日本が生んだキラーコンテンツの一つにマンガがあります.マンガは一般に手書きで描かれたキャラクタがコマの中で自由に動き回り,その考えや感情はセリフによって表現されています.また,ストーリーの展開を追うことや,通常ではありえない時間的・空間的な飛躍があっても,人間はその内容を理解し,楽しむことが可能です.別の見方をすると,マンガは種々雑多な記号の集合であり,人間はそこからさまざまな情報を読み取ることができます.本研究室では,このような現象を工学的に説明すること,および自動解析によってマンガというメディアの新たな可能性を探ることを目的として,原作者や出版社のご協力のもと,実際に連載中の作品を対象としたマンガの機械解析に関する研究を進めています.
Manga is one of Japan’s most influential cultural exports. Typically presented in black-and-white, manga features hand-drawn fictional characters who move freely within panels, expressing their thoughts and emotions through dialogue. Despite narrative leaps in time and space that defy real-world logic, human readers can follow and enjoy the story with ease. From another perspective, manga can be viewed as a complex collection of symbolic elements that humans intuitively interpret. Our laboratory aims to provide an engineering explanation of this phenomenon and to explore new directions for manga as a medium through automatic analysis. With the collaboration of professional manga authors and publishers, we are conducting research on machine-based analysis of serialized manga works.
Agro-Engineering Research
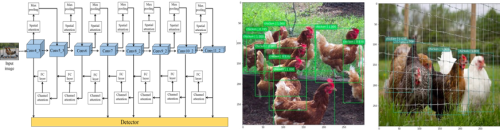
動植物を対象に,機械学習を用いた健康管理や行動解析を行うことで,動物福祉やリスク管理に貢献する技術の開発を進めています.技術的な課題としては,データ収集にかかるコストや,人間では起こり得ない状況や行動をいかにモデル化するかが挙げられます.一方で,対象となる動植物特有の生態に着目することで,従来にはなかった新たな知見を得られる可能性がある点も,本研究の魅力です.
We are developing technologies that contribute to animal welfare and risk management by applying machine learning to the health monitoring and behavioral analysis of animals and plants.Technical challenges include the high cost of data collection and the difficulty of modeling situations and behaviors that do not occur in humans.On the other hand, focusing on the unique biology of each species may lead to unexpected insights, which is another compelling aspect of this research.
Multi-Sensor Anomaly Detection
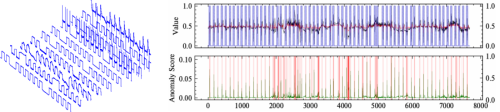
マルチセンサーから得られる温度,湿度,加速度,映像などの多様なデータを統合的に解析し,通常とは異なるパターンや挙動を検出する技術です.このような異常検知は,機器の故障予兆,動植物の異常行動,環境変化の早期察知などに応用され,リスク管理や効率的な運用に貢献します.
This technology involves the integrated analysis of diverse data obtained from multiple sensors, such as temperature, humidity, acceleration, and video, to detect patterns or behaviors that deviate from the norm.Such anomaly detection can be applied to early warning of equipment failure, abnormal behavior in animals or plants, and early detection of environmental changes, contributing to effective risk management and operational efficiency.
AI-Based Technical Assistance

本研究では,AIを用いた作画支援技術の開発に取り組んでいます.具体的には,キャラクターイラストの制作過程において,AIがポーズの下書き(ラフスケッチ)の自動生成,線画のクリンナップ,自動着彩などを支援します.これにより,作業時間の短縮や品質の安定化が可能となり,マンガ・アニメ制作や教育支援,個人クリエイターの創作活動など,幅広い分野への応用が期待できます.
In this research, we are developing AI-based techniques to support the illustration process.Specifically, our system assists in various stages of character illustration production, such as automatic pose sketching (rough drawing), line art cleanup, and colorization.These technologies help reduce production time and ensure consistent quality, making them applicable to a wide range of fields including manga and animation production, educational tools, and creative support for individual artists.